11 KiB
title, subtitle, date, lastmod, slug, draft, author, description, keywords, license, comment, weight, tags, categories, collections, hiddenFromHomePage, hiddenFromSearch, hiddenFromRss, hiddenFromRelated, summary, resources, toc, math, lightgallery, password, message, repost
| title | subtitle | date | lastmod | slug | draft | author | description | keywords | license | comment | weight | tags | categories | collections | hiddenFromHomePage | hiddenFromSearch | hiddenFromRss | hiddenFromRelated | summary | resources | toc | math | lightgallery | password | message | repost | ||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 使用 Ollama 在RTX 4090上部署 DeepSeek R1 Distill 系列模型并优化 | 2025-02-08T18:29:29-05:00 | 2025-02-08T18:29:29-05:00 | ollama-deepseek-r1-distill | false |
|
本篇文章详细介绍了如何利用DeepSeek-R1及其蒸馏模型在消费级硬件上的应用,并探讨了其性能优化和不足之处。同时提供了安装Ollama及创建深度定制化模型的步骤,以及一些提高运行效率的方法,包括使用Flash Attention和KV Cache量化等技巧。 |
|
true | 0 |
|
|
|
false | false | false | false | 本篇文章详细介绍了如何利用DeepSeek-R1及其蒸馏模型在消费级硬件上的应用,并探讨了其性能优化和不足之处。同时提供了安装Ollama及创建深度定制化模型的步骤,以及一些提高运行效率的方法,包括使用Flash Attention和KV Cache量化等技巧。 |
|
true | false | true |
|
前言
最近DeepSeek-R1爆火,原因有多种。不光价格便宜,性能强劲还开源。更难能可贵的是官方放出了几个蒸馏模型,包含各个尺寸。
- deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
- deepseek-ai/DeepSeek-R1-Distill-Llama-8B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B
这使得一般的消费级硬件也有机会体验Reasoning模型的魅力。不过请注意,这和真正的DeepSeek-R1相差甚远。即便是DeepSeek-R1-Distill-Qwen-32B也只是达到o1-mini级别的水平。
这一点可以参考官方给出的图表(下面这张图是可以交互的,你可以关闭你不想要的数据)。
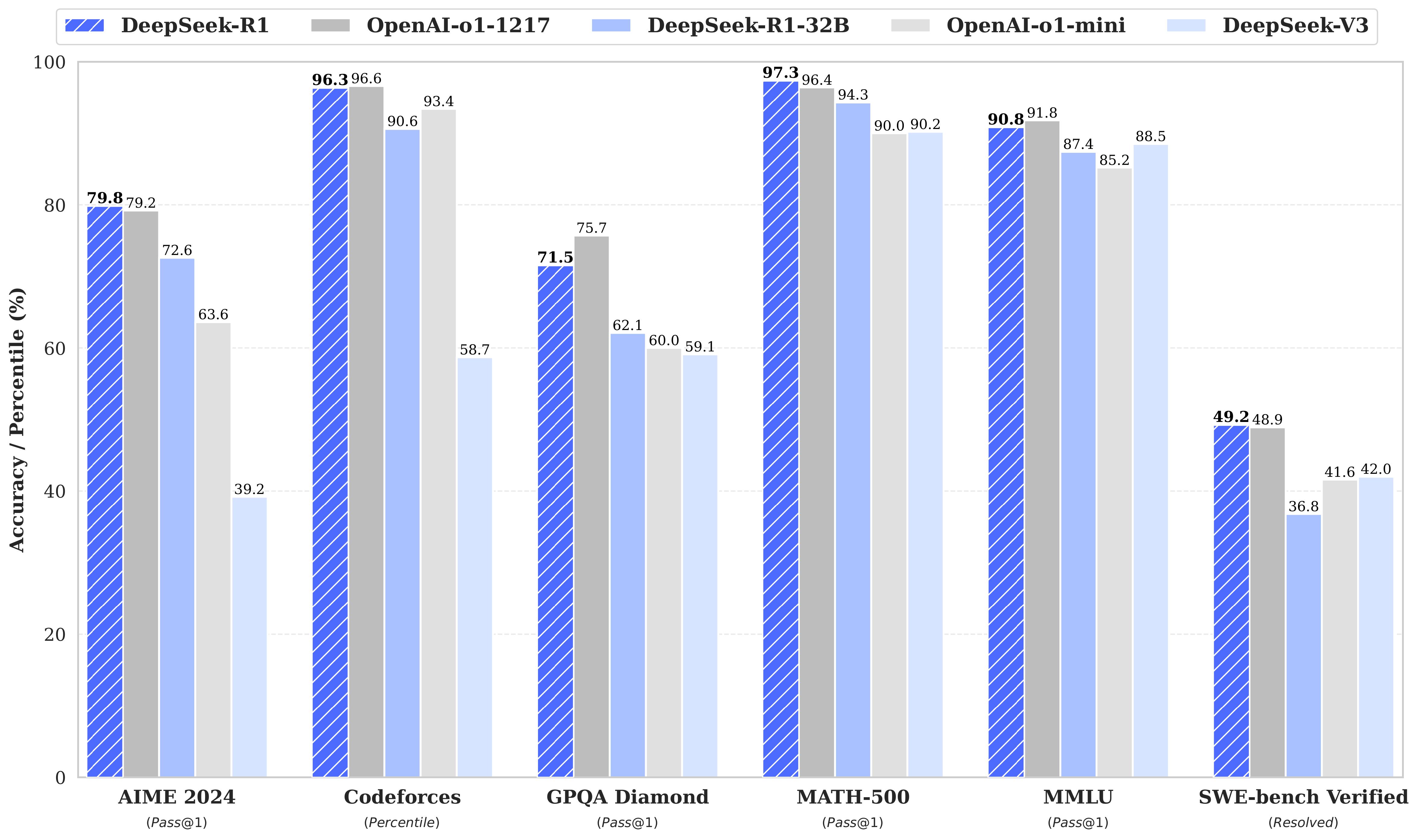{kind=link}
{{< echarts >}} { "tooltip": { "trigger": "axis", "axisPointer": { "type": "shadow" } }, "legend": { "top": 30, "data": [ "DeepSeek-R1", "OpenAI-o1-1217", "DeepSeek-R1-32B", "OpenAI-o1-mini", "DeepSeek-V3" ] }, "grid": { "left": "8%", "right": "8%", "bottom": "10%", "containLabel": true }, "xAxis": { "type": "category", "data": [ "AIME 2024\n(Pass@1)", "Codeforces\n(Percentile)", "GPQA Diamond\n(Pass@1)", "MATH-500\n(Pass@1)", "MMLU\n(Pass@1)", "SWE-bench Verified\n(Resolved)" ], "axisLabel": { "interval": 0 } }, "yAxis": { "type": "value", "min": 0, "max": 100, "name": "Accuracy / Percentile (%)", "nameGap": 32, "nameLocation": "center" }, "series": [ { "name": "DeepSeek-R1", "type": "bar", "data": [79.8, 96.3, 71.5, 97.3, 90.8, 49.2], "barGap": "0", "label": { "show": true, "position": "top" } }, { "name": "OpenAI-o1-1217", "type": "bar", "data": [79.2, 96.6, 75.7, 96.4, 91.8, 48.9], "label": { "show": true, "position": "top" } }, { "name": "DeepSeek-R1-32B", "type": "bar", "data": [72.6, 90.6, 62.1, 94.3, 87.4, 36.8], "label": { "show": true, "position": "top" } }, { "name": "OpenAI-o1-mini", "type": "bar", "data": [63.6, 93.4, 60.0, 90.0, 85.2, 41.6], "label": { "show": true, "position": "top" } }, { "name": "DeepSeek-V3", "type": "bar", "data": [39.2, 58.7, 59.1, 90.2, 88.5, 42.0], "label": { "show": true, "position": "top" } } ] } {{< /echarts >}}
Ollama提供了更方便使用和管理模型的接口和工具,它的后端是llama.cpp。一个基于CPU推理优化的工具,也支持GPU。
{{< gh-repo-card-container >}} {{< gh-repo-card repo="ollama/ollama" >}} {{< gh-repo-card repo="ggerganov/llama.cpp" >}} {{< /gh-repo-card-container >}}
安装Ollama
这个根据Download Ollama的指引完成即可。我的环境如下:
- 操作系统是Windows 11
- GPU是NVIDIA RTX 4090
- CPU是Intel 13900K
- 内存是128G DDR5
创建模型
在安装好Ollama后,我们就需要创建模型了。一种办法是直接从Ollama Library拉取。
ollama pull deepseek-r1:32b-qwen-distill-q4_K_M
不过这样拉取的模型的默认上下文长度是4096。这显然不够用也不合理,所以我们要修改一下。
一种办法是直接修改Modelfile。如果你不知道一个模型的Modelfile可以执行以下命令查看它的Modelfile。
ollama show --modelfile deepseek-r1:32b-qwen-distill-q4_K_M
这里我给出我用的Modelfile,可以新建一个文本文件保存,比如叫做DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.txt。
FROM deepseek-r1:32b-qwen-distill-q4_K_M
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}"""
PARAMETER stop <|begin▁of▁sentence|>
PARAMETER stop <|end▁of▁sentence|>
PARAMETER stop <|User|>
PARAMETER stop <|Assistant|>
PARAMETER num_ctx 16000
它包含多个部分,我们暂时用不着改太多,只需要注意FROM表明构建使用的模型(告诉Ollama用什么构建),以及num_ctx的值(默认4096,除非通过API请求的时候有额外设置)这里我设置的16000,它就是上下文长度,越长消耗的显存/内存,计算资源就越多。
Note
经过测试,RTX 4090差不多可以在KV Cache量化为q8_0,启用Flash Attention的情况下运行32B q4_K_M量化模型的同时,保持16K的上下文长度。如果同等情况下运行14B q4_K_M量化模型可以达到64K的上下文长度。有关KV Cache量化和Flash Attention的内容我会稍后讲解。
当我们创建好Modelfile后就可以使用如下命令创建模型了。
ollama create DeepSeek-R1-Distill-Qwen-32B-Q4_K_M -f DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.txt
Tip
其格式如下:
ollama create <要创建的模型名> -f <Modelfile的路径和名字>
在此过程中Ollama会拉取模型并且创建它,完成后可以执行ollama list检查模型列表,你应该会看见类似的东西。
PS C:\Users\james\Desktop\Ollama> ollama list
NAME ID SIZE MODIFIED
DeepSeek-R1-Distill-Qwen-32B-Q4_K_M:latest ca51e8a9d628 19 GB 2 days ago
deepseek-r1:32b-qwen-distill-q4_K_M 5de93a84837d 19 GB 2 days ago
优化
Ollama支持多个优化参数,它们通过环境变量控制。
OLLAMA_FLASH_ATTENTION:1开启,0关闭OLLAMA_HOST:Ollama监听的IP,默认是127.0.0.1,如果要对外服务需要改成0.0.0.0OLLAMA_KV_CACHE_TYPE:默认fp16,可以设置q8_0,或者q4_0OLLAMA_NUM_PARALLEL:同时运行的请求数,越多吞吐量越大,显存/内存消耗越多,一般1就差不多了OLLAMA_ORIGINS:有关CORS跨站请求的内容,如果你要在其它地方请求Ollama,特别域名不一样的话你要设置对应的域,或者设置*允许所有来源
Flash Attention是必开的,KV Cache我建议选q8_0,实测发现q4_0会让R1的思考长度下降,这可能是因为内容都比较长,上下文比较重要。
Windows 11
要在Windows 11中设置环境变量,需要进入“高级系统设置”,
{{< image src="system-properties.avif" width="320px" caption="System Properties" >}}
然后选择“环境变量”,之后选择“新建”。重启Ollama使其生效。
{{< image src="environment-variables.avif" width="480px" caption="Environment Variables" >}}
MacOS
在MacOS中可以执行诸如
launchctl setenv OLLAMA_FLASH_ATTENTION "1"
launchctl setenv OLLAMA_KV_CACHE_TYPE "q8_0"
的命令来设置环境变量。重启Ollama使其生效。
Linux
在Linux中,在安装完Ollama后可以修改ollama.service文件来修改它的环境变量。
sudo systemctl edit ollama.service
然后在[Service]下添加Environment字段,类似这样
[Service]
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_KV_CACHE_TYPE=q8_0"
保存修改后重载
sudo systemctl daemon-reload
sudo systemctl restart ollama
不足
Ollama使用的后端llama.cpp并非是为了多并发和高性能的生产环境设计的。比如它对多GPU的支持就不是很理想,它会把模型的层拆分到多个GPU里,这样解决了显存不足的问题,但是这样导致在单一时间内,只有一块GPU在干活。要同时利用多张GPU的性能,我们需要张量并行,这是SGLang或者vLLM擅长的。
至于性能,在和SGLang或者vLLM对比的时候也不占优势,吞吐量远不及后者。其次对多模态模型的支持有限,适配进度缓慢。
客户端
为了更方便使用Ollama中的模型,我推荐两个客户端。Cherry Studio是我觉得好用的本地客户端,LobeChat是我觉得好用的云端客户端(我之前写过一篇 使用 Docker Compose 部署 LobeChat 服务端数据库版本)
{{< gh-repo-card-container >}} {{< gh-repo-card repo="CherryHQ/cherry-studio" >}} {{< gh-repo-card repo="lobehub/lobe-chat" >}} {{< gh-repo-card repo="Calcium-Ion/new-api" >}} {{< gh-repo-card repo="immersive-translate/immersive-translate" >}} {{< /gh-repo-card-container >}}
New API则是我觉得一个很好的,用来集中管理API并且以OpenAI API格式提供服务的工具。Immersive Translate则是一个好评如潮的翻译插件,它支持调用OpenAI API来进行翻译,也自然可以与Ollama以及New API组合搭配。翻译效果远超传统翻译方法。